3.1 运算器的设计方法
运算器所具有的只是简单的算术、逻辑运算以及移位、计数等功能。计算机中对数据信息加工的基本思想:将各种复杂的运算处理分解为最基本的算术运算和逻辑运算。
运算器逻辑组织结构设计通常可以分为以下层次:
(1)根据机器字长,将N个一位全加器通过加法进位链连接构成N位并行加法器(加快进位的形成)。
(2)利用多路选择逻辑在加法器的输入端实现多种输入组合,将加法器扩展为多功能的算术/逻辑运算部件。
(3)根据乘除运算的算法,将加法器与移位器组合,构成定点乘法器与除法器。将计算定点整数的阶码运算器和计算定点小数的尾数运算器组合构成浮点运算器(软件实现)。
(4)在算术/逻辑运算部件的基础上,配合各类相关的寄存器,构成计算机中的运算器。
3.2 定点补码加减运算
3.2.1 补码加减运算的基础
补码运算指参加运算的操作数均用补码表示,并且运算结果也用补码表示。补码表示可以把减法转换为加法,大大简化了加减运算算法,所以在计算机中均采用补码加减运算。
1.补码加法
$[x]补+[y]补=[x+y]_补(mod)M (3-1)$
若$x,y$是定点小数,则$Mod=2$;若$x,y$是定点整数,则$Mod=2^n$,$n$为运算器字长。
2.补码减法
$[x]补-[y]补=[x]补+[-y]补=[x-y]_补 (3-2)$
若$x,y$是定点小数,则$Mod=2$;若$x,y$是定点整数,则$Mod=2^n$,$n$为运算器字长。
补码运算的基本规则:(1)参加运算的各个操作数均以补码表示,运算结果仍以补码表示。(2)符号位与数值位一样参加运算。(3)若求和,则将两补码数直接相加,得到两数之和的补码;若求差,则将减数变补(由$[y]补$求$[-y]补$),然后与被减数相加,得到两数之差的补码。(4)补码总是对确定的模而言,若运算结果超过模(有从符号位上产生的进位),则将模自动丢弃。
正(负)溢出:两个正(负)数相加(减)的结果大(小)于机器所能表示的最大(小)正(负)数。出现溢出后,机器将无法表示,因此必须正确判别溢出并及时加以处理。
3.2.2 溢出判断与变形补码
设参加运算的操作数为$[x]补=x_f.x_n\dots x_2x_1,[y]补=yf.y_n\dots y2y1$,$[x]补+[y]补$的和为$[s]补=s_f.s_n\dots s_2s_1$,发生溢出时$OVR=1$。常用的判断溢出的方法如下。
1.根据两个操作数的符号与结果的符号判别溢出
由于都是定点数,所以只有同号相加才可能溢出,溢出的条件为
$OVR=(x_f\oplus s_f)(y_f\oplus s_f) (3-3)$
即$x_f$和$y_f$均与$s_f$不同时,产生溢出。
2.根据两数相加时产生的进位判别溢出
设$Cf$为符号位上的进位,$C{n-1}$为最高数值位上产生的进位,则溢出的条件为
$OVR=Cf\oplus C{n-1} (3-4)$
即若进入符号位的进位和从符号位上产生的进位不相等,则产生溢出。
3.采用变形补码进行运算
如果使用两个符号位,即使因出现溢出侵占了一个符号位,仍能保持最左边符号是正确的。
变形补码是用两个符号位表示的补码,也称双符号位补码,其实质是将模扩大。
纯小数的变形补码
纯整数的变形补码
变形补码的形式为$[x]{变形补}=x{f1}x{f2}.x_n\dots x_2x_1$,设和的变形补码为$[s]{变形补}=s{f1}s{f2}.s_n\dots s_2s_1$,变形补码的溢出判断条件为
$OVR=s{f1}\oplus s{f2}$
即当结果的两个符号位不一致时,出现溢出,其中$s{f1}s{f2}$为00或11表示正常补码,01表示正溢出,10表示负溢出。
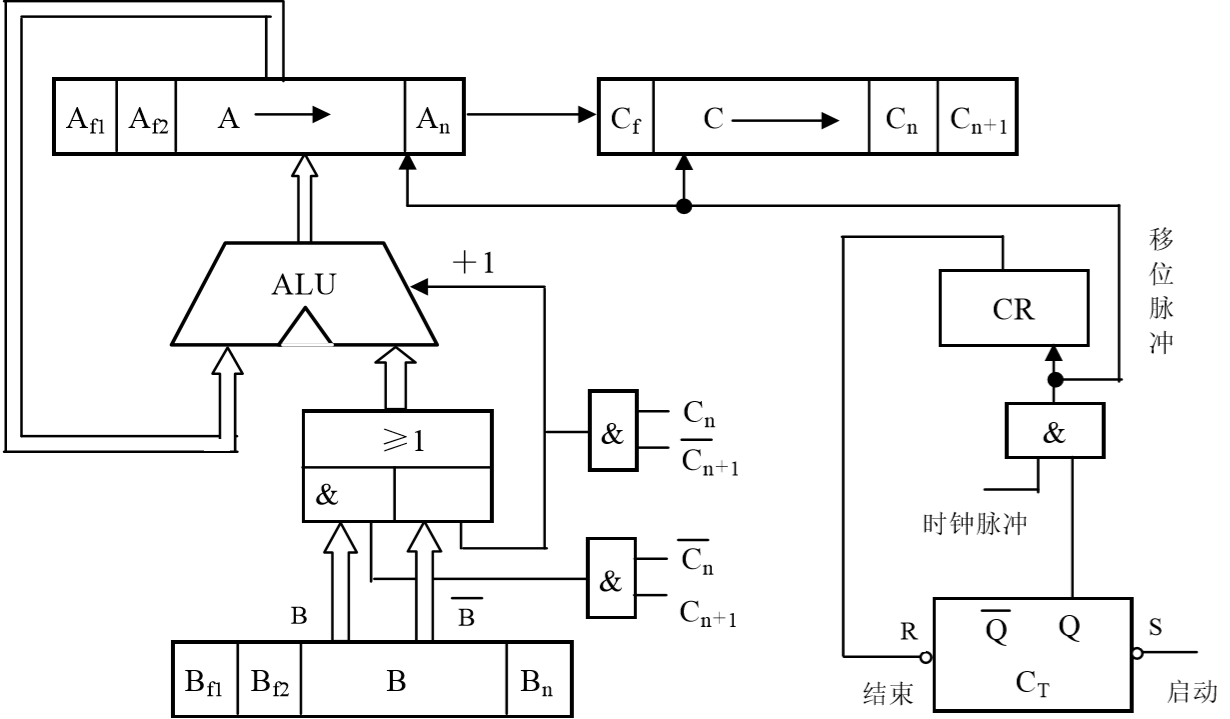
3.2.3 算术逻辑运算部件
运算器的基本功能是进行算术逻辑运算,其最基本也是最核心的部件是加法器。在加法器的输入端加入多种输入控制功能,就能将加法器扩展为多功能的算术/逻辑运算部件。
1.补码加减运算的逻辑实现
根据$[A]补+[B]补=[A+B]补$,$[A]补-[B]补=[A]补+[-B]补=[A]补+[B]补+1=[A-B]补$。
补码加减运算的硬件实现电路基本原理仍是加法器,只要在加法器的$A、B$输入端增加控制信号,即可控制实现加法和减法。因为$B\oplus1=\overline{B}$,所以在需要作减法时,将输入到加法器的$B$端的内容取反后送入加法器,并使最低进位$C_0=1$,即可实现减法运算。
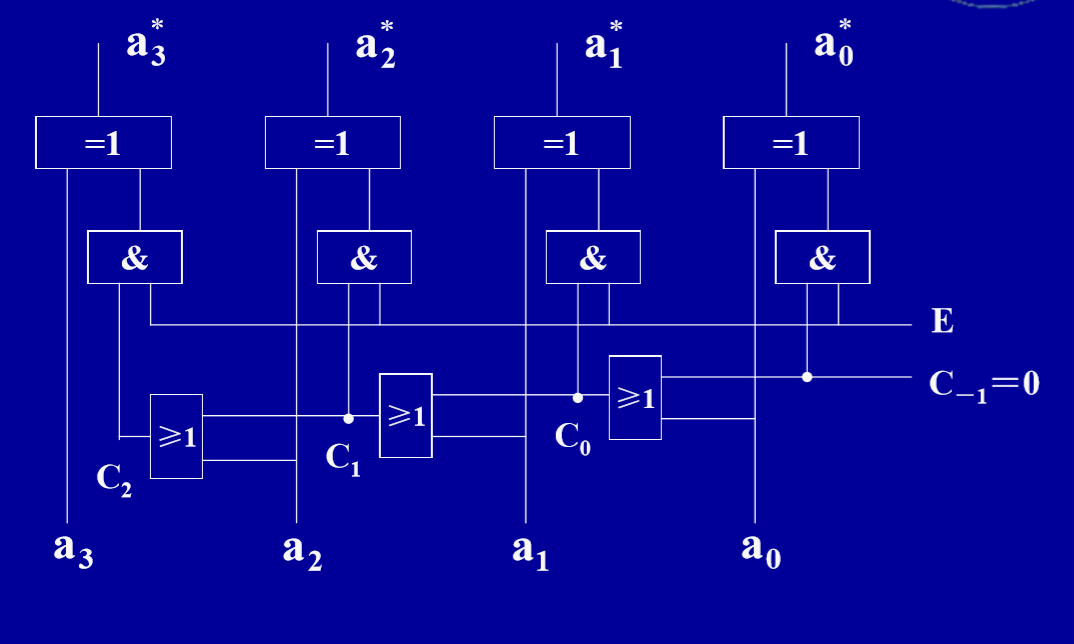
采用串行进位的补码加减运算逻辑电路
M=0,$Bi\oplus0=B_i$,$C_0=0$,作$A+B$;M=1,$B_i\oplus1=B_i$,$C_0=1$,作$A-B$。电路中刚才用进出符号位的进位进行溢出判断$OVR=C_n\oplus C{n-1}$
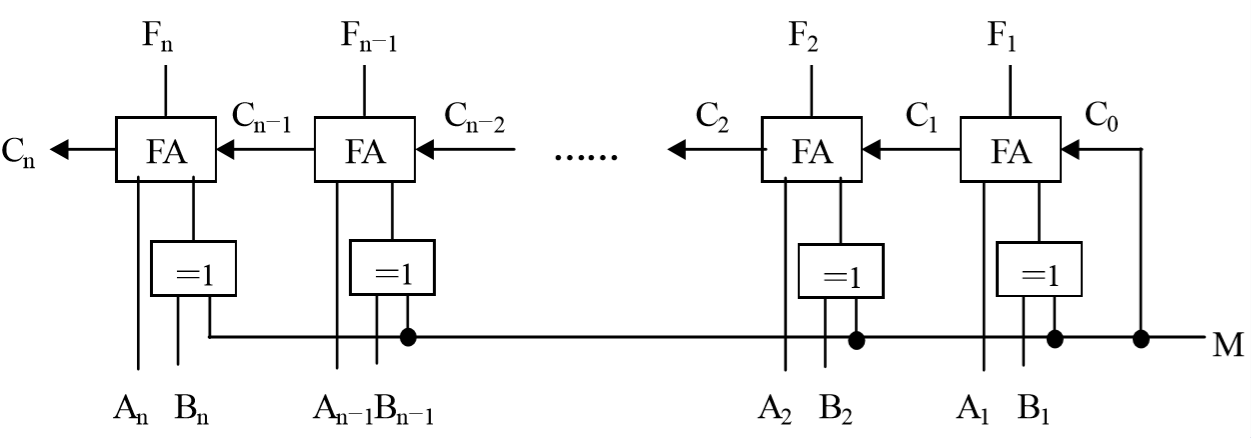
2.实现补码加减运算逻辑电路
两个操作数需要存放在能连接到ALU的寄存器中,运算时送到运算器中进行运算,运算结果再送到寄存器(称累加寄存器(accumulator))中保存。控制器通过对指令操作码译码得到操作含义,向运算器发出控制信号。
补码加减运算的逻辑电路
3.算术逻辑运算部件举例
算术逻辑运算单元(ALU)是一种以加法器为基础的多功能组合逻辑电路,基本设计思想是在加法器输入端加入一个“函数发生器”,这个函数发生器可以在多个控制信号的控制下,为加法器提供不同的输入函数,从而构成一个具有较完善的算术、逻辑运算功能的运算部件。
3.3 定点乘法运算
计算机中实现乘除运算通常采用三种方式:利用乘除运算子程序;加法器基础上增加左右移位及计数器等逻辑线路构成乘除运算部件;设置专用的阵列乘除运算器。
3.3.1 原码乘法运算
参加运算的被乘数和乘数均用原码表示,运算时符号位单独处理,被乘数与乘数的绝对值相乘,所得的积也采用原码表示。在定点机中,两个数的原码乘法运算包括乘积的符号处理和两数绝对值相乘。
设被乘数$[x]原=x_f.x_1x_2\dots x_n$,乘数$[y]原=yf.y_1y_2\dots y_n$,乘积$[z]原=[x]原\times[y]原=[x\times y]_原=z_f.z_1z_2\dots z_n$。乘积的符号$z_f=x_f\oplus y_f$。
1.一位原码乘法运算
设参加运算的被乘数为$x=0.x_1x_2x_3x_4$,乘数为$y=0.y_1y_2y_3y_4$,有
根据上式,可将乘法转换为一系列加法与移位操作,将递推公式推广到n位,得:
其中$Z_0$到$Z_n$称为部分积。可以把乘法转换为一系列加法与移位操作。
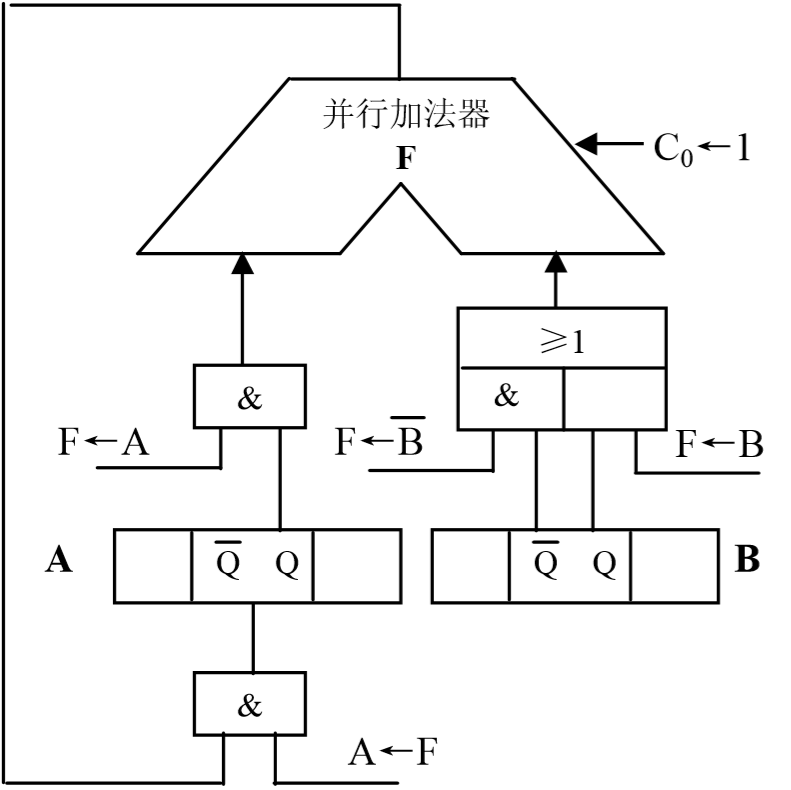
算法:(1)积的符号单独按两操作数的符号异或得到,用被乘数和乘数的数值部分进行运算。(2)以乘数的最低位作为乘法判别位,若判别位为1,则在前次部分积(初始为0)上加上被乘数,然后连同乘数一起右移一位;若判别位为0,则在前次部分积上加0,然后连同乘数一起右移一位。(3)重复第2步直到运算n次为止。n为乘数数值部分的长度,结果存放在累加器(高位部分)和乘数寄存器(低位部分)中。(4)将乘积的符号与数值部分结合,即可得到最终结果。
3.3.2 补码乘法运算
因为补码运算简单,因此不少机器采用补码乘法,常用的有布斯乘法。
1.补码一位乘法
以定点小数为例,设被乘数x的补码为$[x]补=x_0.x_1x_2\dots x_n$,乘数y的补码为$[y]补=y0.y_1y_2\dots y_n$,乘积为$[z]补=[x\times y]_补$。
(1)被乘数x的符号任意,乘数y为正数,即:$[x]补=x_0.x_1x_2\dots x_n$,$[y]补=0.y1y_2\dots y_n$,有$[x]补=2+x=2^{n+1}+x(Mod2)$,$[y]补=y$,$[x]补\times[y]补=2^{n+1}y+x\times y=2\times(y_1y_2\dots y_n)+x\times y(Mod2)$,因为$y_1y_2\dots y_n$为大于0的整数,根据模2性质,$2\times(y_1y_2\dots y_n)=2(Mod2)$,所以$[x]补\times[y]补=2+x\times y=[x\times y]补$,因为$y>0,[y]补=y,y_0=0$,所以$[x\times y]补=[x]补\times[y]补=[x]补\times y=[x]补\times(0.y1y_2\dots y_n)=[x]补\times(\sum_{i=1}^ny_i2^{-i})$。
(2)被乘数x的符号任意,乘数y为负数,即:$[x]补=x_0.x_1x_2\dots x_n$,$[y]补=1.y1y_2\dots y_n=2+y(Mod2)$,因为$y=[y]补-2=0.y1y_2\dots y_n-1$,所以$x\times y=x\times(0.y_1y_2\dots y_n)-x$,得$[x\times y]补=[x\times(0.y1y_2\dots y_n)]补-[x]补$,因为$0.y_1y_2\dots y_n>0$,所以$[x\times(0.y_1y_2\dots y_n)]补=[x]补\times(0.y_1y_2\dots y_n)$,得$[x\times y]补=[x]补\times(0.y_1y_2\dots y_n)-[x]补$。
(3)设被乘数x和乘数y均为任意符号数,将情况1、2综合,得
令部分积的初始值$[z0]补=0$,得部分积的递推形式:
补码一位乘法的算法
(1)参加运算的数均以补码表示,符号位参加运算且部分积与被乘数采用双符号位。
(2)乘数末位增设附加位$y{n+1}$,且初始$y{n+1}=0$。
(3)以$yny{n+1}$作为乘法判别位,执行以下操作。

(4)重复上面第(3)步,共做n+1次,最后一次不移位。
补码一位乘法的算法,乘积的符号是在运算过程中自然形成的,不需要加以特别处理,这是与原码乘法的重要区别。
当x=-1,y=-1时,求$[x\times y]_补$所得到的结果为+1,结果溢出无意义,是定点小数补码乘法中唯一的溢出情况。
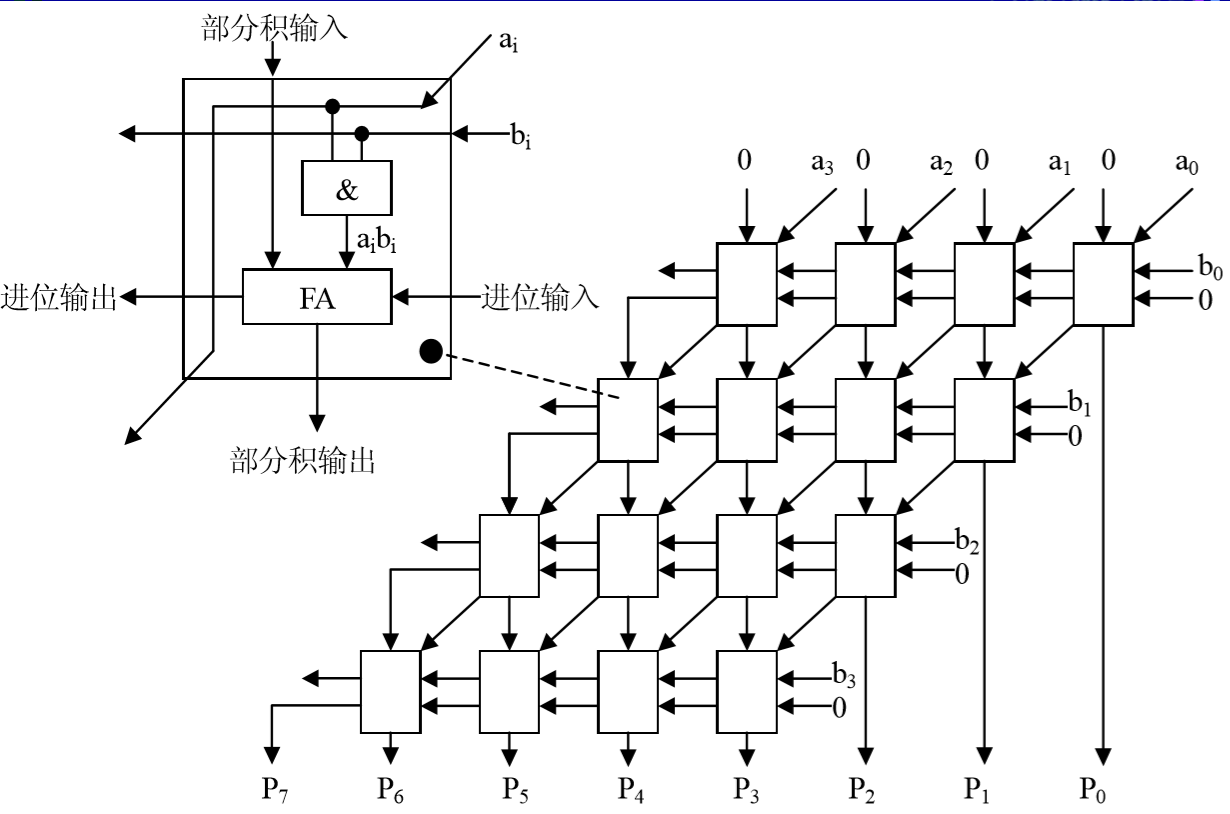
3.3.3 快速乘法运算
阵列乘法器的基本思想:把大量加法器单元电路按一定阵列形式排列,直接实现手算算式的运算过程,提高速度。
1.不带符号的阵列乘法器
2.带符号的阵列乘法器
多了求补器,可实现原码和补码乘法。
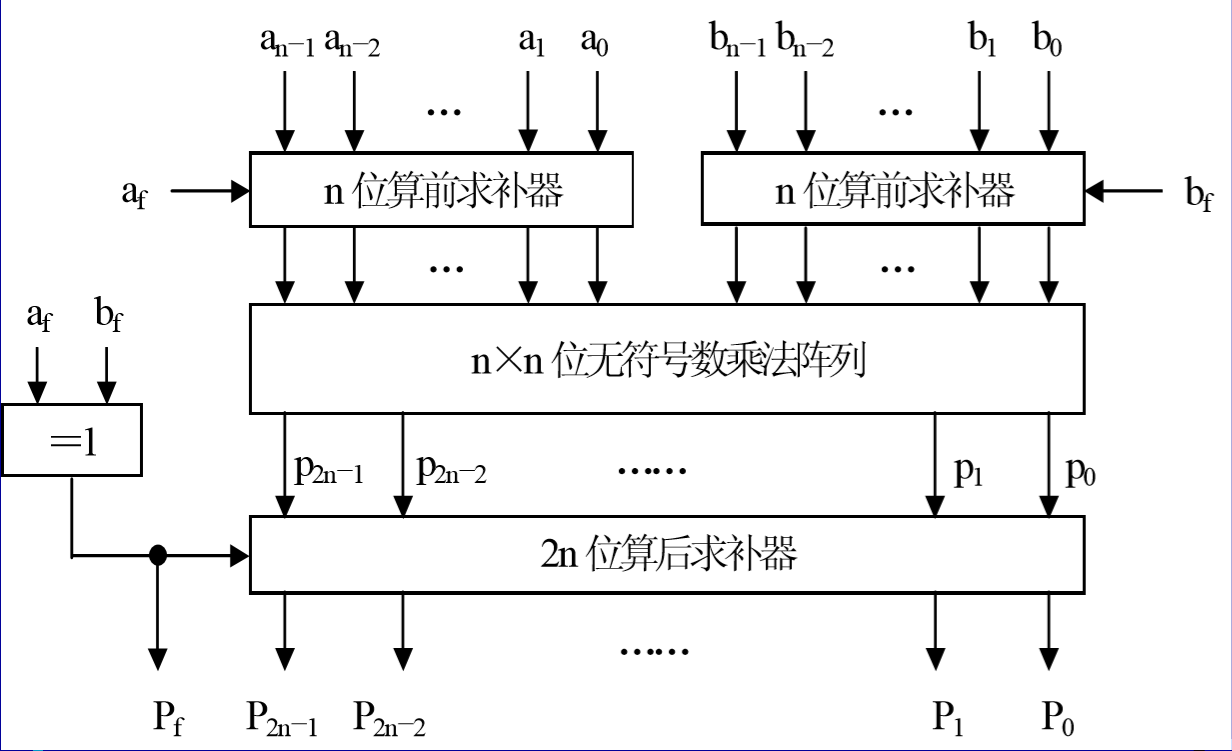
一个二进制对2求补器电路的逻辑表达式为:
$E$为控制信号,0不求补,1求补,可以利用符号位来作为控制信号E。