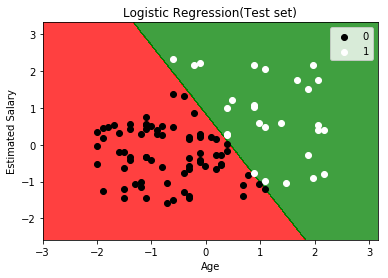
逻辑回归|第6天
Steps
Datasets
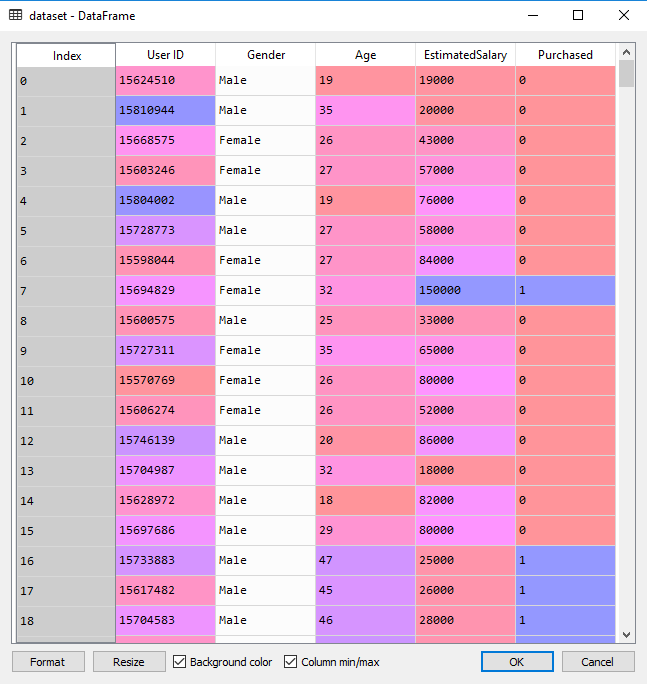
数据集包含了社交网络中用户的信息。这些信息涉及用户ID,性别,年龄以及预估薪资。一家汽车公司刚刚推出了他们新型的豪华SUV,尝试预测哪些用户会购买这种全新SUV。并且在最后一列用来表示用户是否购买。将建立一种模型来预测用户是否购买这种SUV,该模型基于两个变量,分别是年龄和预计薪资。因此特征矩阵将是这两列。我们尝试寻找用户年龄与预估薪资之间的某种相关性,以及他是否购买SUV的决定。
Code
第1步:数据预处理
1 | #导入库 |
第2步:逻辑回归模型
该项工作的库将会是一个线性模型库,之所以被称为线性是因为逻辑回归是一个线性分类器,这意味着在二维空间中,两类用户(购买和不购买)将被一条直线分割。然后导入逻辑回归类。下一步将创建该类的对象,它将作为训练集的分类器。
1 | #将逻辑回归应用于训练集 |
第3步:预测
1 | #预测测试集结果 |
第四步:评估预测
预测了测试集。 现在将评估逻辑回归模型是否正确的学习和理解。因此这个混淆矩阵将包含模型的正确和错误的预测。
1 | #生成混淆矩阵 |
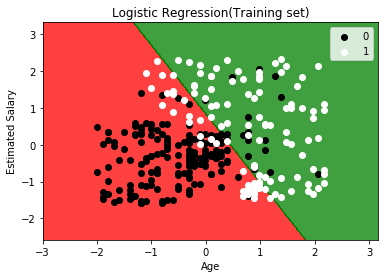
训练集可视化
1 | from matplotlib.colors import ListedColormap |
测试集可视化
1 | X_set,Y_set=X_test,Y_pred |