k近邻法(k-NN)|第11天
Steps

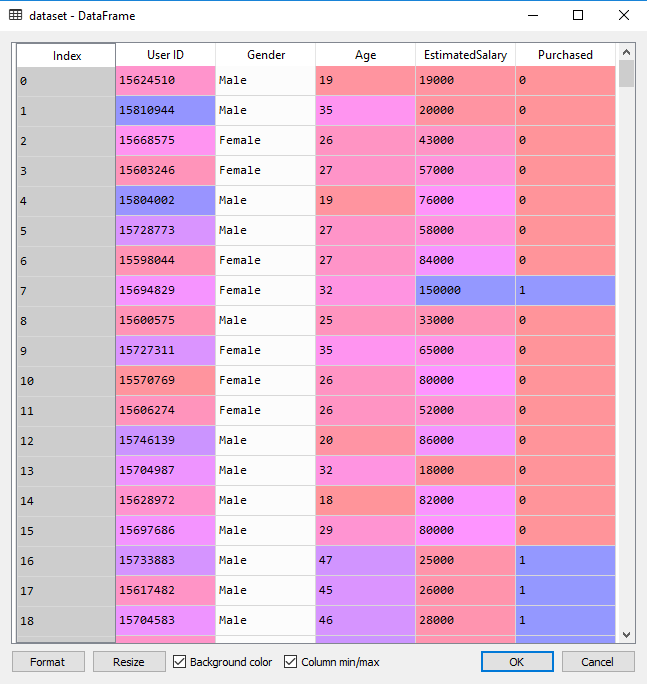
Datasets
Code
第1步:数据预处理
1 | #导入相关库 |
第2步:使用K-NN对训练集数据进行训练
1 | #使用K-NN对训练集数据进行训练 |
第3步:预测
1 | #对测试集进行预测 |
第四步:评估预测
1 | #生成混淆矩阵 |
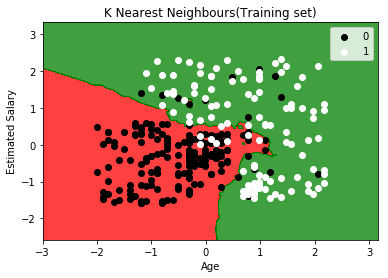
训练集可视化
1 | from matplotlib.colors import ListedColormap |
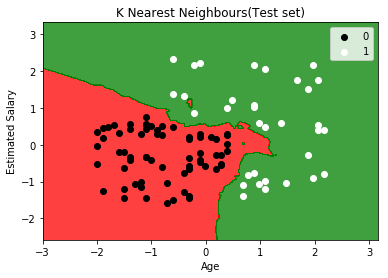
测试集可视化
1 | X_set,Y_set=X_test,Y_pred |
1 | #导入相关库 |
1 | #使用K-NN对训练集数据进行训练 |
1 | #对测试集进行预测 |
1 | #生成混淆矩阵 |
1 | from matplotlib.colors import ListedColormap |
1 | X_set,Y_set=X_test,Y_pred |